




How to Train a Machine Learning Model Using Python has become a foundational technology across industries, from enhancing customer experiences with chatbots to forecasting market trends. If you are new to this field or looking to strengthen your skill set, learning how to train machine learning models with Python is an essential first step.
Python has emerged as the preferred language for ML due to its simplicity, readability, and extensive ecosystem of libraries. In this guide, we will cover everything from preparing data to building, training, evaluating, and tuning your machine learning models.
Table of Contents
What is Machine Learning?
Machine learning is a branch of artificial intelligence that allows computers to learn patterns from data and make decisions or predictions without being explicitly programmed.
Unlike traditional programming, where every rule is hard-coded, ML algorithms identify patterns, relationships, and trends in data to make informed decisions.
The goal of machine learning is to create models that can generalize effectively to new, unseen data. Learning how to train machine learning models with Python involves selecting the right algorithm, feeding it data, and evaluating its performance.
Why Use Python for Machine Learning?
Python has become the go-to language for ML due to several reasons:
- Readable Syntax: Python’s clear syntax allows beginners to grasp concepts quickly.
- Extensive Libraries: Tools like Scikit-Learn, TensorFlow, Keras, and PyTorch make model building easier.
- Active Community: Python has a vibrant community, providing resources, tutorials, and support for troubleshooting.
Python provides a robust foundation for building, training, and deploying ML models effectively.ng models effectively.
Setting Up Your Python Environment
Before we dive into the coding part, you’ll need to set up your Python environment. Follow these steps:
- Install Python: Download and install the latest version of Python from python.org.
- Install a Package Manager: Use
pip(which comes with Python) to install packages. Alternatively, you can install Anaconda for an integrated environment that simplifies package management. - Install Required Libraries: For machine learning, the key libraries you’ll need include:
numpy: For numerical operations.pandas: For data manipulation.scikit-learn: For machine learning algorithms.matplotlibandseaborn: For data visualization.
You can install them via pip:
bashCopyEditpip install numpy pandas scikit-learn matplotlib seaborn
Once the environment is set up, you’re ready to start training your machine learning model using Python.
Preparing Your Data
Data preparation is crucial to the success of your machine learning model. Your model can only learn from data that is clean, well-structured, and relevant. The process of preparing your data involves several steps:
- Loading Data: You can load your dataset using Pandas.
pythonCopyEditimport pandas as pd
data = pd.read_csv('your_dataset.csv')
- Exploratory Data Analysis (EDA): Understand the structure of your data by performing basic operations like:
- Checking for missing values (
data.isnull().sum()). - Displaying summary statistics (
data.describe()). - Visualizing the data with graphs (histograms, scatter plots).
- Checking for missing values (
- Data Cleaning: Handle missing values, outliers, and duplicates. You can either drop or fill missing data depending on your analysis.
- Feature Selection: Identify which columns are most relevant for your model. You may want to drop irrelevant or redundant features.
- Splitting the Data: Divide your dataset into training and testing sets. Typically, 80% is used for training, and 20% for testing.
pythonCopyEditfrom sklearn.model_selection import train_test_split
X = data.drop('target_column', axis=1)
y = data['target_column']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
By now, your data should be ready to feed into a machine learning model using Python.
Choosing the Right Machine Learning Model
Selecting the appropriate machine learning algorithm depends on the type of problem you’re trying to solve:
- Classification: When the output variable is categorical (e.g., predicting if an email is spam or not). Popular algorithms include Logistic Regression, Decision Trees, and Random Forest.
- Regression: When the output variable is continuous (e.g., predicting house prices). Common algorithms include Linear Regression and Support Vector Regression (SVR).
- Clustering: When you want to group similar data points (e.g., customer segmentation). Common clustering algorithms include K-means and DBSCAN.
For this tutorial, we’ll focus on training a classification model using Logistic Regression.
Training the Model
Now that your data is ready and you’ve chosen the algorithm, it’s time to train your machine learning model using Python.
pythonCopyEditfrom sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score
# Initialize the model
model = LogisticRegression()
# Train the model
model.fit(X_train, y_train)
# Make predictions on the test set
y_pred = model.predict(X_test)
# Evaluate the model
accuracy = accuracy_score(y_test, y_pred)
print(f'Model Accuracy: {accuracy * 100:.2f}%')
Evaluating the Model
After training, it’s essential to evaluate how well your model performs. Common evaluation metrics for classification include:
- Accuracy: The percentage of correctly predicted instances.
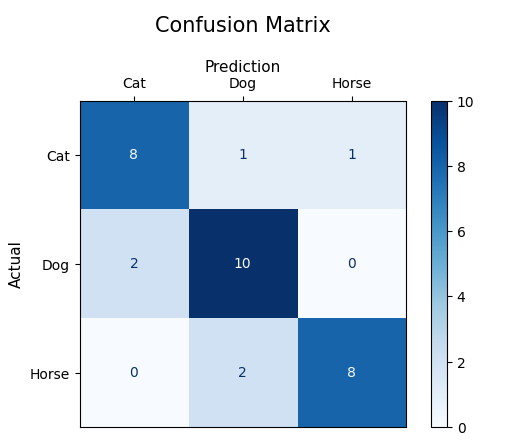
- Confusion Matrix: A table that shows the number of correct and incorrect predictions, categorized by type.
- Precision, Recall, F1-Score: These metrics are useful when dealing with imbalanced datasets.
pythonCopyEditfrom sklearn.metrics import confusion_matrix, classification_report
# Confusion Matrix
cm = confusion_matrix(y_test, y_pred)
print('Confusion Matrix:')
print(cm)
# Classification Report
cr = classification_report(y_test, y_pred)
print('Classification Report:')
print(cr)
Tuning the Model
Once you have a baseline model, you can further improve its performance by tuning its hyperparameters. GridSearchCV is a powerful tool for finding the best combination of parameters.
pythonCopyEditfrom sklearn.model_selection import GridSearchCV
# Define the parameter grid
param_grid = {'C': [0.1, 1, 10], 'solver': ['liblinear', 'saga']}
# Initialize GridSearchCV
grid_search = GridSearchCV(LogisticRegression(), param_grid, cv=5)
# Fit the model
grid_search.fit(X_train, y_train)
# Print the best parameters
print('Best Parameters:', grid_search.best_params_)
Final Thoughts
Training a machine learning model using Python is a highly rewarding process that involves several critical steps. From data preparation and model selection to training, evaluation, and tuning, Python provides the tools and flexibility needed to build powerful, reliable machine learning models. With Python’s rich ecosystem of libraries, such as Pandas, Scikit-learn, and Matplotlib, developers can seamlessly integrate data manipulation, model development, and performance visualization to create high-quality solutions.
By following the steps outlined in this guide, you now have a solid understanding of how to train a machine learning model using Python. You are equipped to build your own models, fine-tune them, and evaluate their performance to ensure they meet your specific needs. The beauty of machine learning using Python is that it allows for continuous learning and improvement; by testing different algorithms, modifying hyperparameters, and optimizing your models, you can achieve better accuracy and make more reliable predictions.
One of the key elements to success in training a machine learning model using Python is iteration. As you experiment with new techniques and analyze model results, you’ll uncover new ways to improve and refine your models. It’s this cycle of testing, tweaking, and optimizing that leads to success in machine learning.
As you continue to build and deploy machine learning models using Python, remember that the journey doesn’t stop once the model is trained. Keep exploring new algorithms, learning about advanced techniques, and implementing performance improvements to take your models to the next level. Python’s versatility in machine learning will empower you to keep innovating and building better models for diverse applications.. Stay Tuned !!!


